Funsearch
Why this paper matters
This paper shows a key thing: LLMs can serve as hypothesis generators / a mechanism for local search, providing a direction of improvement with respect to a few samples. As discussed in weaknesses, I don’t think it establishes that LLMs are necessarily good at this, but they do seem capable of it. That’s exciting!Summary
We would like to create a program that maximizes some desired property. The key here is that we have the ability to score each of these programs. To take an example, we might have a bin packing problem and would like to learn a program that suggests which bin we should place an item into next. An example score could then be the negative of the total number of bins used e.g. pack efficiently (note, this is not actually the score they used). A simplified version of the procedure, neglecting some details for clarity, then runs as follows:Note, the islands are being used to create some diversity in the procedure. Every 4 hours they kill half of the islands and restart them with new random programs.
They then show that in 4/140 runs they manage to find a 512 size capset in dimension 8 (if you want to know what a capset is, the Set example on Wikipedia is pretty good: Cap set)and pretty consistently improve over some bin-packing heuristics.
A really rough summary figure, taken from the paper is below.
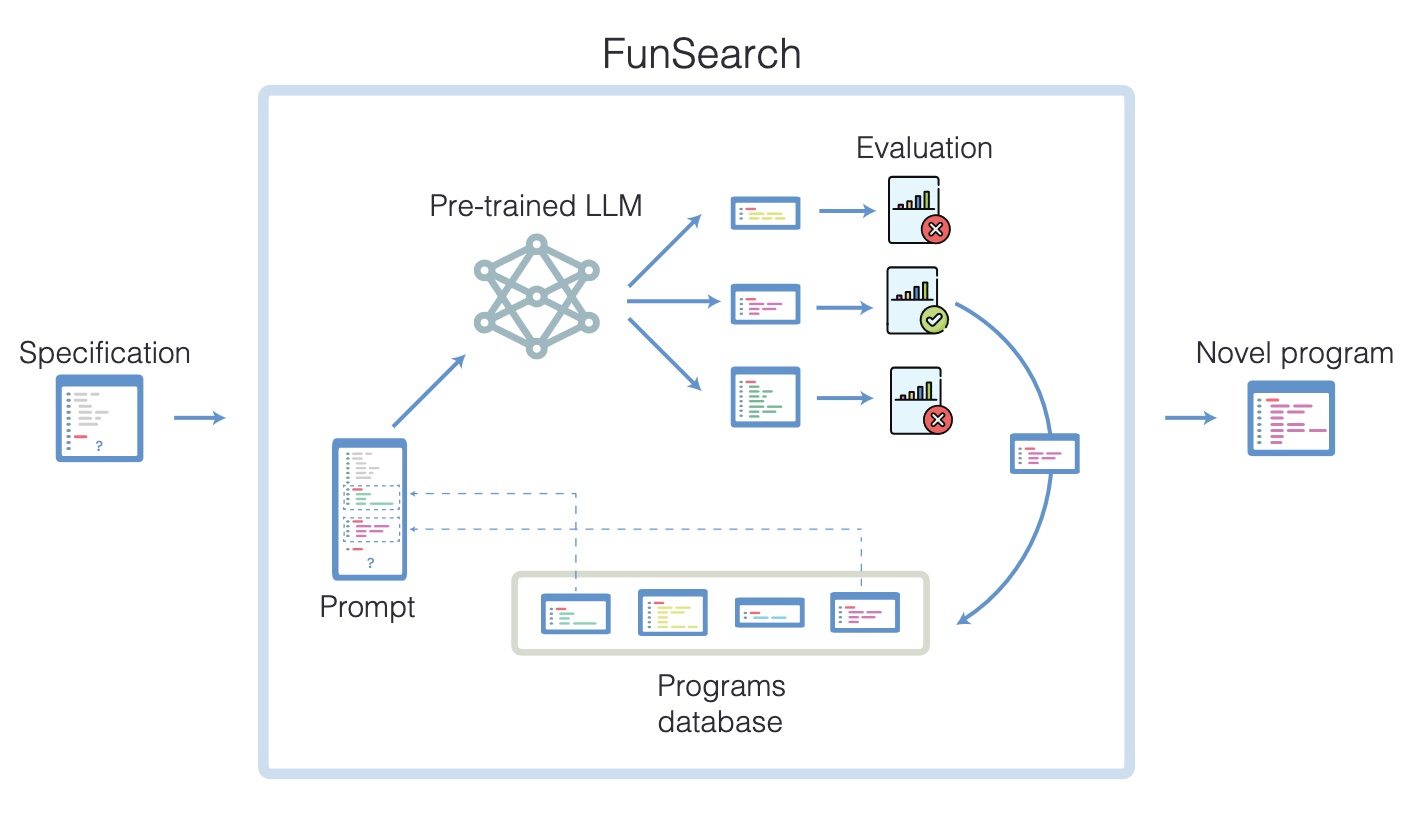
Follow-up work
This paper, the ones out already like it (Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models) and the hordes of others like it yet to be published, clearly represent an incoming wave of LLMs hooked up to verifiers that can be used to automate processes. That's important because anytime you can automate something, well, that's productivity growth right there.
Weaknesses
a. LLMs in this paper serve two functions. They allow you to (1) generate arbitrary programs that are likely syntactically correct and (2) they also serve to generate program improvements. This former component serves as a pretty significant advantage over other automated approaches you might take to this problem like genetic algorithms or RL; those approaches are likely to spend a long time generating invalid programs. However, as a consequence, we’re not really sure how good the LLM is at the actual program improvement component. The paper provides evidence that they are doing some kind of program improvement but without a baseline or more careful study, it’s hard to tell exactly how good it is. I think there’s a really good paper to be published here trying to figure out just how creative LLMs are at generating local improvements in this way.
b. It’s clearly pretty not robust.