Eugene Vinitsky*, Nathan Lichtlé*, Xiaomeng Yang*, Brandon Amos, Jakob Foerster
In submission, NeurIPS Datasets and Benchmarks Track
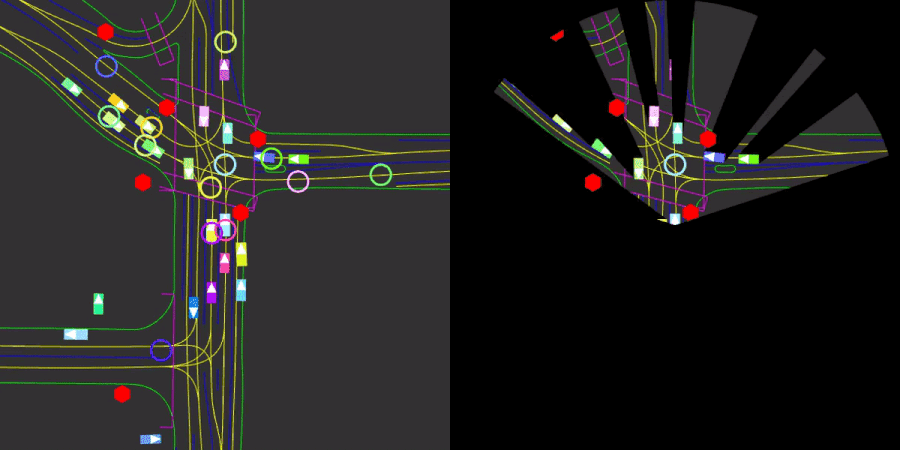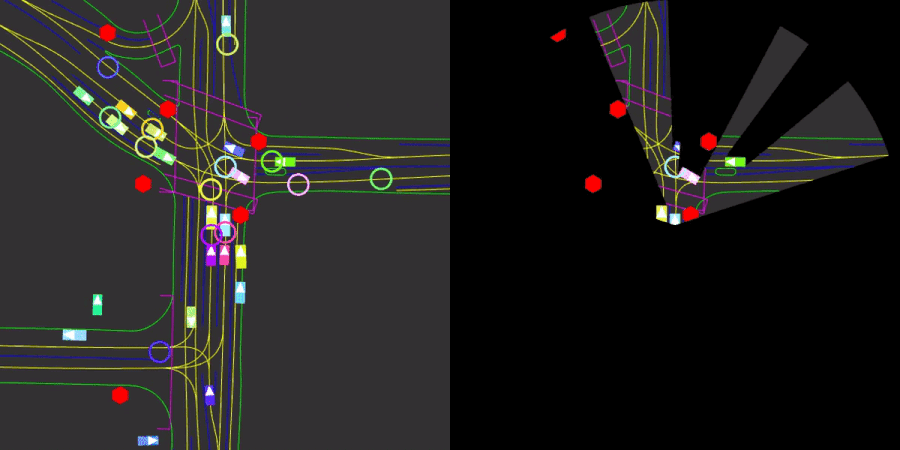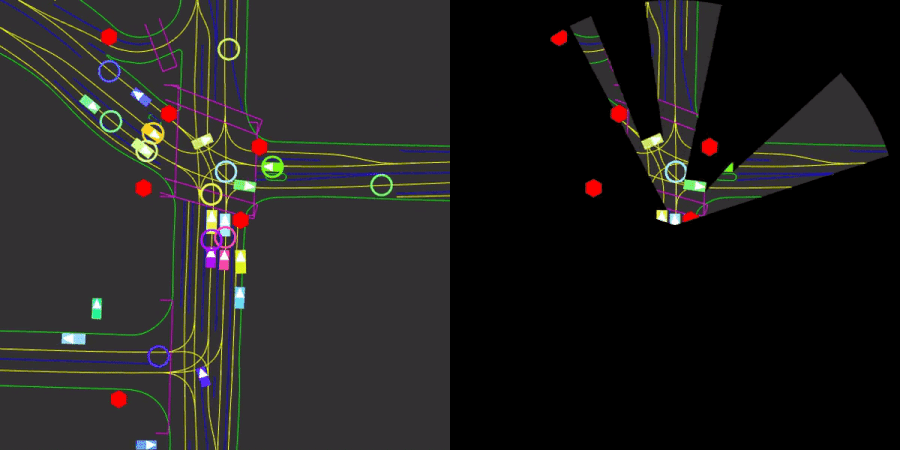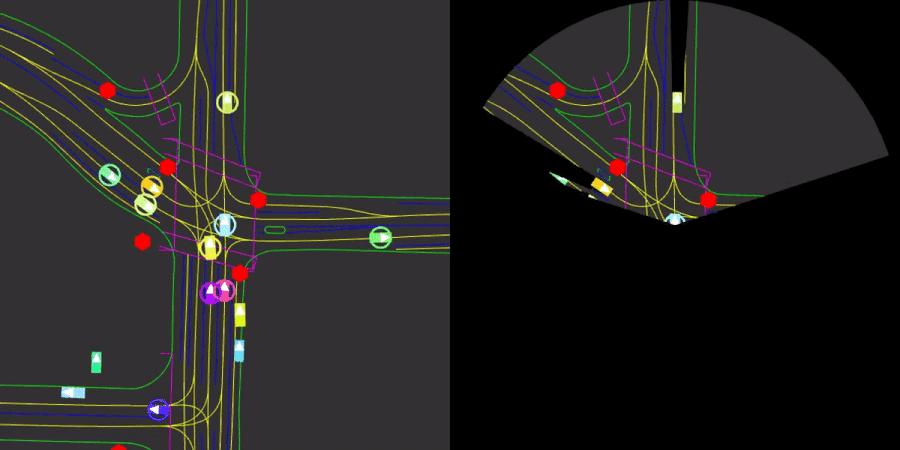
We introduce Nocturne, a new 2D, data-driven driving simulator for investigating multi-agent coordination under partial observability. The focus of Nocturne is to enable research into inference and theory of mind in real-world multi-agent settings without the computational overhead of computer vision and feature extraction from images. Agents in this simulator only observe an obstructed view of the scene, mimicking human visual sensing constraints. Nocturne uses efficient intersection methods to compute a vectorized set of visible features in a C++ back-end, allowing the simulator to run at 2000+ steps-per-second. We show that baseline RL / IL agents are nowhere near human-level performance on this task.

Eugene Vinitsky*, Nathan Lichtle*, Matthew Nice*, Benjamin Seibold, Dan Work, Alexandre Bayen
ICRA 2022
By combining eight hours of driving data and reinforcement learning algorithms, we design and field-test a new energy-improving cruise controller that is specifically tuned to dampen the waves that actually emerge on the highway. Using a single radar-equipped vehicle, we collect data from the I-24 in Tennessee and use it to construct a single lane simulator that is used to train our controller. We then validate our controller by deploying it on four autonomous vehicles during congestion and confirm that controller behavior matches simulated behavior.
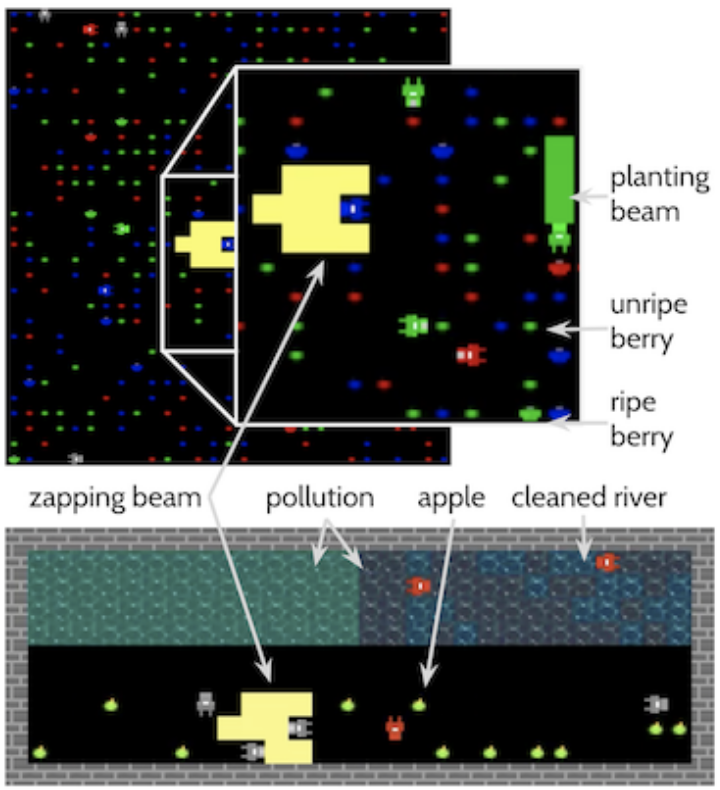
Eugene Vinitsky, Raphael Köster, John P Agapiou, Edgar Duéñez-Guzmán, Alexander Sasha Vezhnevets, Joel Z Leibo
In preparation, Collective Intelligence
Multi-agent RL algorithms coordinate well in fully centralized settings but struggle in decentralized settings. Human society, on the other hand, is great at this, developing all sorts of norms and conventions to discourage free-riding and enable collaboration. Taking inspiration from models of norms as classifiers on approved behavior, we construct an agent architecture that enables agents to rapidly converge on group norms that select coordinated equilibria and penalize free-riding agents.
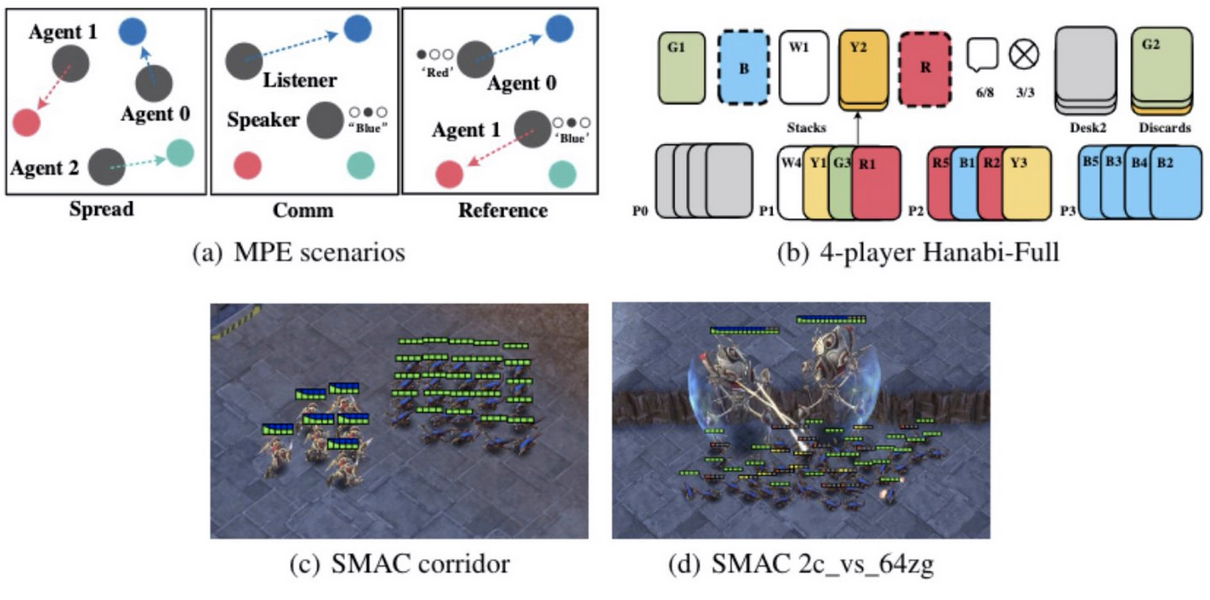
C Yu, A Velu, E Vinitsky, Y Wang, A Bayen, Y Wu
In submission, NeurIPS Datasets and Benchmarks Track
Proximal Policy Optimization (PPO) is a popular on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent settings. This is often due the belief that on-policy methods are significantly less sample efficient than their off-policy counterparts in multi-agent problems. In this work, we investigate Multi-Agent PPO (MAPPO), a variant of PPO which is specialized for multi-agent settings. Using a 1-GPU desktop, we show that MAPPO achieves competitive performance, sample efficiency, and wall-clock time in three popular multi-agent testbeds: the particle-world environments, the Starcraft multi-agent challenge, and the Hanabi challenge, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures.
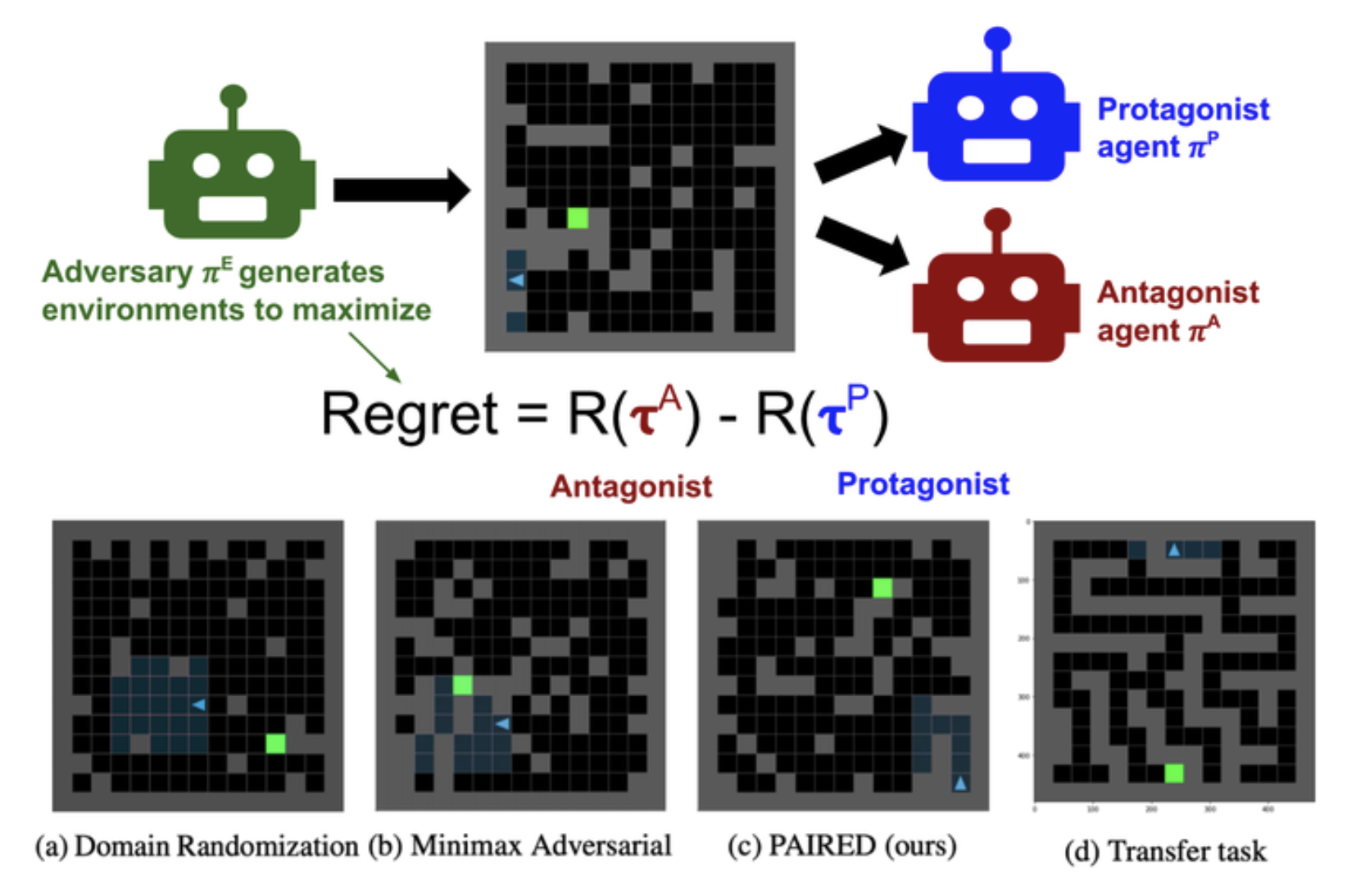
M Dennis, N Jaques, E Vinitsky, A Bayen, S Russell, A Critch, S Levine
NeurIPS, 2020
We want to provide agents with a challenging curriculum but need to ensure that the set of tasks are still feasible; we show that by switching to maximizing regret instead of expected return gives us exactly this property. We introduce PAIRED, a three player game in which an adversary generates tasks that maximize the regret between a pair of agents. We show that applying this procedure yields an agent with good generalization performance in a variety of domains.

Eugene Vinitsky, Kanaad Parvate , Aboudy Kreidieh, Cathy Wu , Alexandre Bayen
Intelligent Transportation Systems Conference, 2018
Code
We introduce an autonomous vehicle (AV) based alternative to ramp metering to improve transportation networks. Ramp metering is the standard technique for maximizing the outflow of traffic bottlenecks but is expensive to maintain. Instead, we can take advantage of readily available cruise controllers to optimize the system. Using reinforcement learning, we design controllers that even at at a low penetration rate of 10%, are able to improve the outflow of a small model of the San-Francisco Oakland Bay Bridge.
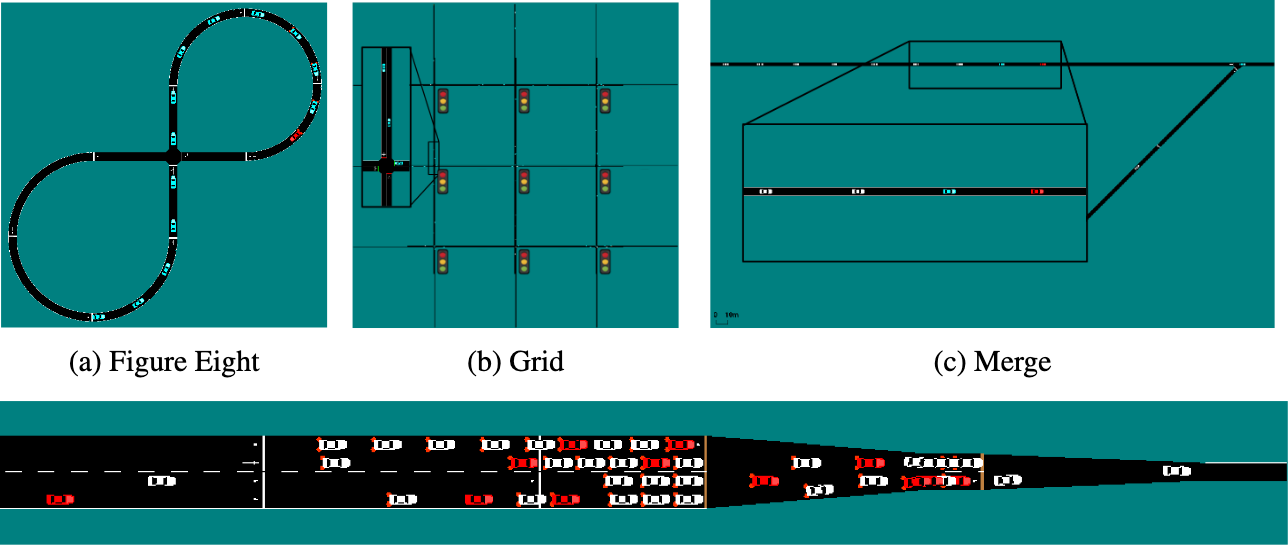
Eugene Vinitsky, Aboudy Kreidieh, Luc Le Flem, Nishant Kheterpal, Kathy Jang, Cathy Wu, Fangyu Wu, Richard Liaw, Eric Liang, Alexandre Bayen
Conference on Robot Learning, 2018
Code / BAIR Blog Post / Coverage in Science
Benchmarks are an essential part of algorithmic computer science/control, making it easy to rank algorithms and control schemes. To remedy the lack of benchmarks in intelligent traffic/autonomous vehicle control we release a set of four new benchmarks. These cover intersections, on-ramp merges, traffic light control, and bottleneck control. We benchmark four standard deep RL algorithms on these tasks and open-source our benchmarks to enable to the community to test their controls against our results.

Behdad Chalaki, Logan Beaver, Benjamin Remer, Kathy Jang, Eugene Vinitsky, Alexandre Bayen, Andreas Malikopoulos
Submission to ICRA, 2019
project page / code
We train an adversary to perturb the states and action spaces of our controller, yielding a controller that is robust to the sim to real gap. we transfer a controller from a simulator to a minicity that is able to efficiently control traffic through a roundabout under variable inflows.

Kathy Jang, Eugene Vinitsky, Behdad Chalaki, Benjamin Remer, Logan Beaver, Andreas Malikopoulos, Alexandre Bayen
ICCPS, 2019
project page / code
We train a vehicle to bring a platoon of vehicles efficiently through a roundabout in a simulator. By adding appropriate Gaussian noise to the state and action space, the controller transfers directly from the simulator with no loss.
Alexandre Bayen, Jesse Goodman, Eugene Vinitsky
COCOA, 2018
arxiv
We introduce a new combinatorial optimization problem: Time Disjoint Walks. This is the natural combinatorial problem that arises when you try to route autonomous vehicles through a network without colissions. We show that for standard DAGs the resulting problem is APX hard and provide tight bounds on the performance of a greedy algorithm.

Cathy Wu, Aboudy Kreidieh, Eugene Vinitsky, Alexandre Bayen
Conference on Robot Learning, 2017
Code \ Project site
We demonstrate that in a variety of settings with mixed human and autonomous vehicles, interesting and unexpected behaviors can emerge. We also introduce the notion of a state equivalence class, a permutation invariant ordering of the inputs, that drastically improves the sample complexity of the RL algorithms.

Cathy Wu , Aboudy Kreidieh, Kanaad Parvate , Eugene Vinitsky, Alexandre Bayen
Code
This paper marked the release of Flow. Flow is a traffic control benchmarking framework. It provides a suite of traffic control scenarios (benchmarks), tools for designing custom traffic scenarios, and integration with deep reinforcement learning and traffic microsimulation libraries. Flow makes pythonic development of traffic control easy and aims to ease the process of studying mixed-autonomy traffic systems.
